
The Impact of High Quality, Low Cost Inference on the AI Landscape: Lessons from DeepSeek
| 6 min readLast week, DeepSeek released another interesting insight into its cost structure and operational efficiencies. Previously, we speculated on their inference costs, and now, they have provided concrete data to support some of our assessments ).
Quick Takeaways
- DeepSeek is achieving inference efficiency that outperforms many competitors while using less powerful hardware.
- Their NVIDIA H800-based system delivers ~1,850 output tokens per second per GPU, 10x outpacing NVIDIA’s own H200 benchmarks.
- DeepSeek requires only ~2,200 GPUs for inference, compared to hyperscalers’ massive multi-billion-dollar data center investments.
- This efficiency lowers AI infrastructure capex requirements, potentially reshaping the competitive landscape for AI service providers and GPU vendors.
Comparing DeepSeek to OpenAI, Claude, Google, and Others
When comparing DeepSeek to OpenAI, Claude, Google, and others, it is worth keeping two things in mind:
First, DeepSeek remains a top-tier model, rivaling closed-source alternatives from OpenAI while outperforming most other models. At Marvin Labs, we have integrated DeepSeek into our AI Investor Co-Pilot workflows and can confidently vouch for its performance.
Second, AI Labs are highly selective in sharing non-benchmark operational data. The transparency provided by DeepSeek is unusual; we have no equivalent visibility into the cost structures of OpenAI, Anthropic, or Google beyond occasional leaks—often with unclear credibility. However, we must acknowledge that DeepSeek likely shares this data selectively, emphasizing elements that portray them favorably.
DeepSeek’s Efficiency: A 10x Leap in Inference Speed
DeepSeek operates on NVIDIA’s H800 GPU, a slightly modified variant of the flagship H100 GPU that remains eligible for export to China ). While the H100 is a cornerstone of NVIDIA’s current Hopper architecture, it is set to be superseded by the upcoming Blackwell platform, promising a new wave of performance enhancements.
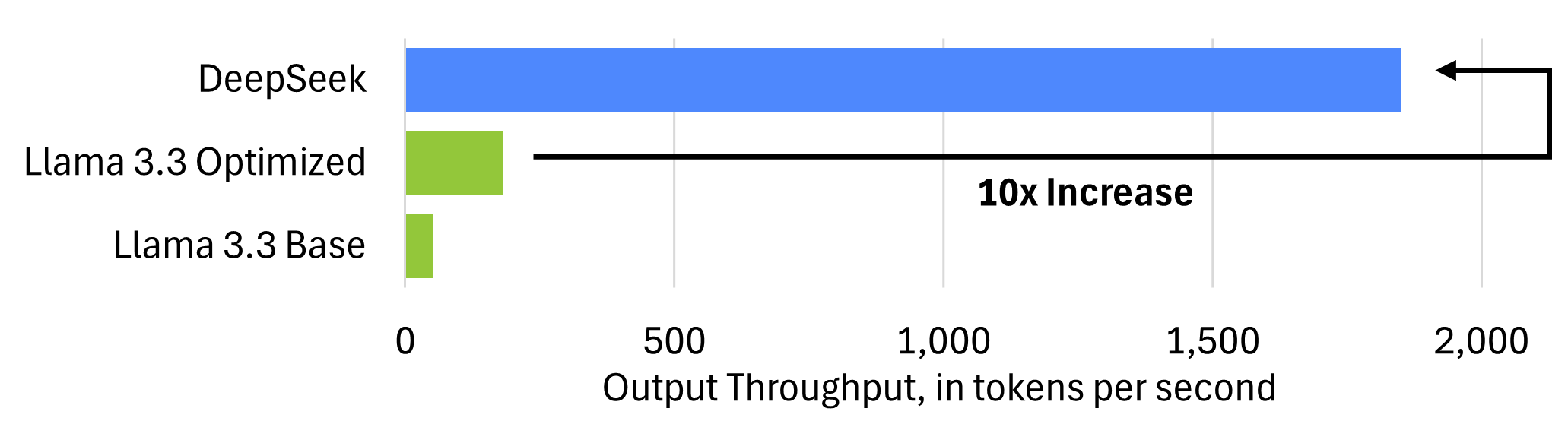
Despite running on what is effectively a constrained version of NVIDIA’s top-tier AI hardware, DeepSeek has achieved an impressive ~1,850 output tokens per second per H800 GPU, according to their latest disclosures. To put this into perspective, NVIDIA’s own benchmark for the H200—a slightly upgraded sibling of the H100—running Meta’s Llama 3.3 70B model peaked at just 181 output tokens per second. This suggests that DeepSeek is operating at over 10 times the efficiency of NVIDIA’s reference numbers, an extraordinary leap in inference optimization.
This dramatic speedup means DeepSeek extracts significantly more value from each GPU it deploys, translating to substantial cost savings and scalability advantages. Even more remarkable is that they achieve this level of efficiency while relying on hardware that, on paper, is less powerful than the cutting-edge setups used by other AI Labs.
Fewer GPUs, Greater Efficiency
DeepSeek’s remarkable efficiency enables them to operate with significantly fewer GPUs for inference than many of their competitors. The company reports running approximately 275 nodes, each equipped with 8 GPUs, for a total of around 2,200 GPUs dedicated to inference. This is a fraction of the GPU clusters deployed by AI hyperscalers, which often require tens of thousands of GPUs to serve similarly complex models at scale.
At an estimated cost of $25,000 per H100 GPU , DeepSeek’s entire inference stack represents an investment of roughly $55 million—a stark contrast to the multi-billion-dollar AI infrastructure expenditures announced by companies like OpenAI, Google DeepMind, and Anthropic. This cost-efficiency is especially notable given the scarcity and high price of cutting-edge GPUs, making DeepSeek’s optimizations a significant competitive advantage in AI deployment economics.
Investment Implications from High-Quality, Low-Cost Inference
DeepSeek’s efficiency raises several key questions for investors about the broader AI infrastructure landscape:
- Can DeepSeek's efficiency scale to other models and AI labs?
Nothing in DeepSeek’s disclosures suggests that their efficiency gains are inherently limited to their own models or infrastructure. Instead, their success appears to be a result of strong engineering and intelligent software optimizations—factors that, in theory, should be transferable. However, the jury is still out on whether these optimizations can be widely replicated across different AI labs and architectures. If they can, it could shift the competitive landscape, favoring companies that focus on software efficiency rather than brute-force compute scaling. - Did hyperscalers overinvest in current-generation GPUs?
In 2024, hyperscalers spent approximately $240 billion on capital expenditures (a 70% increase from the previous year), with much of that going toward acquiring NVIDIA’s H100 and H200 GPUs. Microsoft alone reportedly purchased 485,000 H100 GPUs, making it NVIDIA’s largest customer, while Meta acquired 224,000. Several other hyperscalers made purchases in the 220,000 GPU range (Financial Times ). Given DeepSeek’s demonstration of superior efficiency on fewer GPUs, this raises the question: Did these companies overestimate the compute requirements for AI inference? If so, could we see write-offs or impairments of excess GPU assets in the near future? - Are hyperscaler AI capex projections overly aggressive?
Looking ahead, hyperscalers have announced $330 billion in capital expenditures for 2025, with estimates reaching $400 billion over the next three years. These figures are largely predicated on the assumption that AI demand will continue to accelerate at its current pace. However, if efficiency breakthroughs like DeepSeek’s become more widespread, the projected need for raw compute power could decline significantly. Are we on the verge of a major downward revision in hyperscaler capex plans over the next few quarters? - What happens to GPU vendors if demand collapses and GPUs sit idle?
Much of the recent discussion around NVIDIA has focused on its role as the AI industry’s primary hardware supplier—the classic “selling shovels in a gold rush” narrative. But what happens when the gold rush slows down? If companies realize they have more compute than they need, it could lead to a glut of underutilized GPUs. The Cisco precedent from the Dot-Com era is instructive: when demand for networking equipment suddenly cratered, Cisco not only faced a sharp decline in new orders but also had to compete with its own customers, who were offloading excess inventory acquired during the boom years. If history repeats itself, NVIDIA and other GPU vendors could face a double impact—plunging demand and a flood of second-hand GPUs entering the market.

Alex is the co-founder and CEO of Marvin Labs. Prior to that, he spent five years in credit structuring and investments at Credit Suisse. He also spent six years as co-founder and CTO at TNX Logistics, which exited via a trade sale. In addition, Alex spent three years in special-situation investments at SIG-i Capital.