
DeepSeek's LLM: Disrupting the AI Landscape with Low Inference Costs
| 4 min readDeepSeek, a Chinese AI startup backed by High-Flyer, a quantitative hedge fund, recently launched its latest large language model (LLM), DeepSeek-R1. This release has generated significant attention for its impressive performance and cost-effectiveness but has also raised concerns among existing market leaders.
DeepSeek Offers Lower Inference Costs Than Other Leading Models
DeepSeek is making a notable impact on the market by offering high-quality AI inference at highly competitive rates. The blended cost 1 of the R1 model is $0.65 per 1 million tokens , which is substantially lower than the $26.25 for OpenAI’s o1 model while maintaining comparable quality .
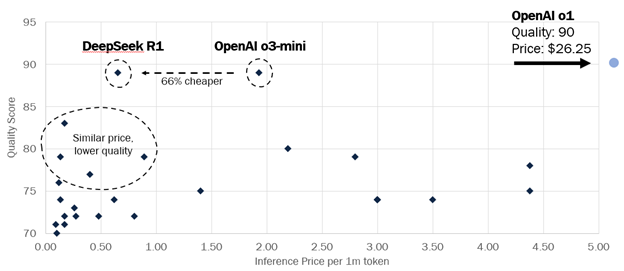
Although the price comparison with the OpenAI o1 model makes for compelling headlines, it’s important to recognize that the o1 model's pricing is an outlier, significantly higher than that of other available models. A more suitable comparison would be with OpenAI's o3-mini model, priced at $1.93 per 1 million tokens . Although it is less expensive than the o1 model, the o3-mini is still of a similar quality. DeepSeek’s pricing is about 66% lower than that of the o3-mini.
Moreover, DeepSeek’s performance matches that of leading OpenAI models regarding quality. As illustrated in the graph above, DeepSeek represents a considerable improvement over other models available at its price point, particularly when compared to Google's suite of Gemini models and Alibaba's Qwen2.5.
The Truth About DeepSeek's Training Costs
There has been much discussion regarding DeepSeek's claim of spending only $5.6 million on training . However, focusing solely on this figure is misleading.
This amount pertains to the training run of a precursor model called DeepSeek V3. The naming conventions in AI can often cause confusion, even among experts. Additionally, the figure represents only the hardware utilization for training and focuses solely on a specific subset of the total costs. It does not account for expenses related to data acquisition, pre-training, innovation training (the advancements in R1 compared to V3), post-training, and research and development. The total expenditure is likely much higher when these additional factors are considered.
No other AI lab—certainly not OpenAI—shares its hardware training costs, making it challenging to gauge how significant a portion of the total model development costs these training expenses truly comprise. Rumors suggest that models like GPT-4o have estimated training costs of around $10-50 million rather than the hundreds of millions or billions often cited. While DeepSeek's training efficiency is impressive, it may not be as groundbreaking as some narratives suggest.
Disrupting the Business Model of AI Labs and Inference Vendors
There is no evidence to suggest that DeepSeek is subsidizing its inference prices below its marginal operating expenses. Although the company operates a successful hedge fund in China, it does not have any outside investors in its AI lab and is unlikely capable of sustaining operating losses at the scale of some venture-backed AI labs.
In contrast, OpenAI reportedly offers its models at or near break-even relative to its marginal operating expenses. The company has incurred losses of $5 billion in FY24 on $3.7 billion of revenue , and CEO Sam Altman has publicly acknowledged that the company is losing money on its “pro” level subscription . This is further underscored by the apparent need to invest $500 billion over the coming years into project “Stargate” to support model training and inference.
Therefore, it is reasonable to conclude that both companies are operating around a break-even point for their respective marginal operating expenses. Given the substantial pricing differences between OpenAI’s and DeepSeek's models, it is thus likely that DeepSeek operates at a significantly lower cost than OpenAI. Such a significant disparity is feasible only if DeepSeek has achieved breakthroughs that enable it to run inference at a substantially lower cost.
As a result, we can anticipate a pricing race to the bottom among AI labs, where most will only be able to recover their marginal operating expenses. Amortizing model development costs will present a considerable challenge for many companies, as it has been thus far. What does that mean for Microsoft, Nvidia, Oracle, and others?
Footnotes
-
Blended cost is the expected cost for 1m tokens calculated as (3 * cost of 1m input tokens + cost of 1m output tokens) / 4. Empirical evidence suggests that the 3 to 1 ratio is a sensible estimate over varying usage scenarios for LLM. ↩

Alex is the co-founder and CEO of Marvin Labs. Prior to that, he spent five years in credit structuring and investments at Credit Suisse. He also spent six years as co-founder and CTO at TNX Logistics, which exited via a trade sale. In addition, Alex spent three years in special-situation investments at SIG-i Capital.